PFLOTRAN has exhibited excellent strong scaling (increasing number of processes on fixed problem size) for years. PFLOTRAN has been applied to a domain size with over 3.34 billion degrees of freedom and run on over 260,000 cores (without HDF5 output) on Jaguar at ORNL. Several examples of PFLOTRAN performance are shown below:
Hanford 300 Area (Flow)
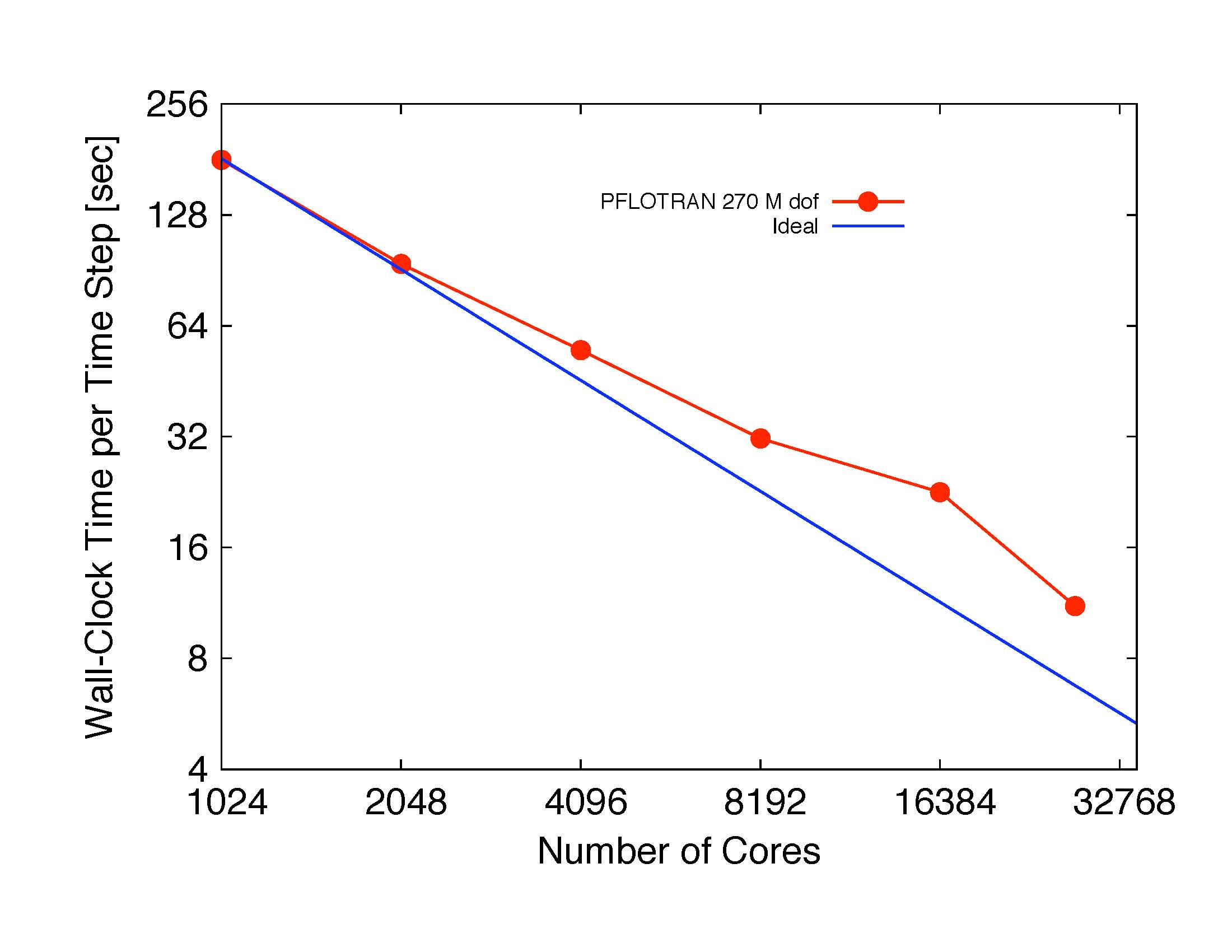
PFLOTRAN strong scalability on 270M degree of freedom variably-saturated flow problem.
Copper leaching
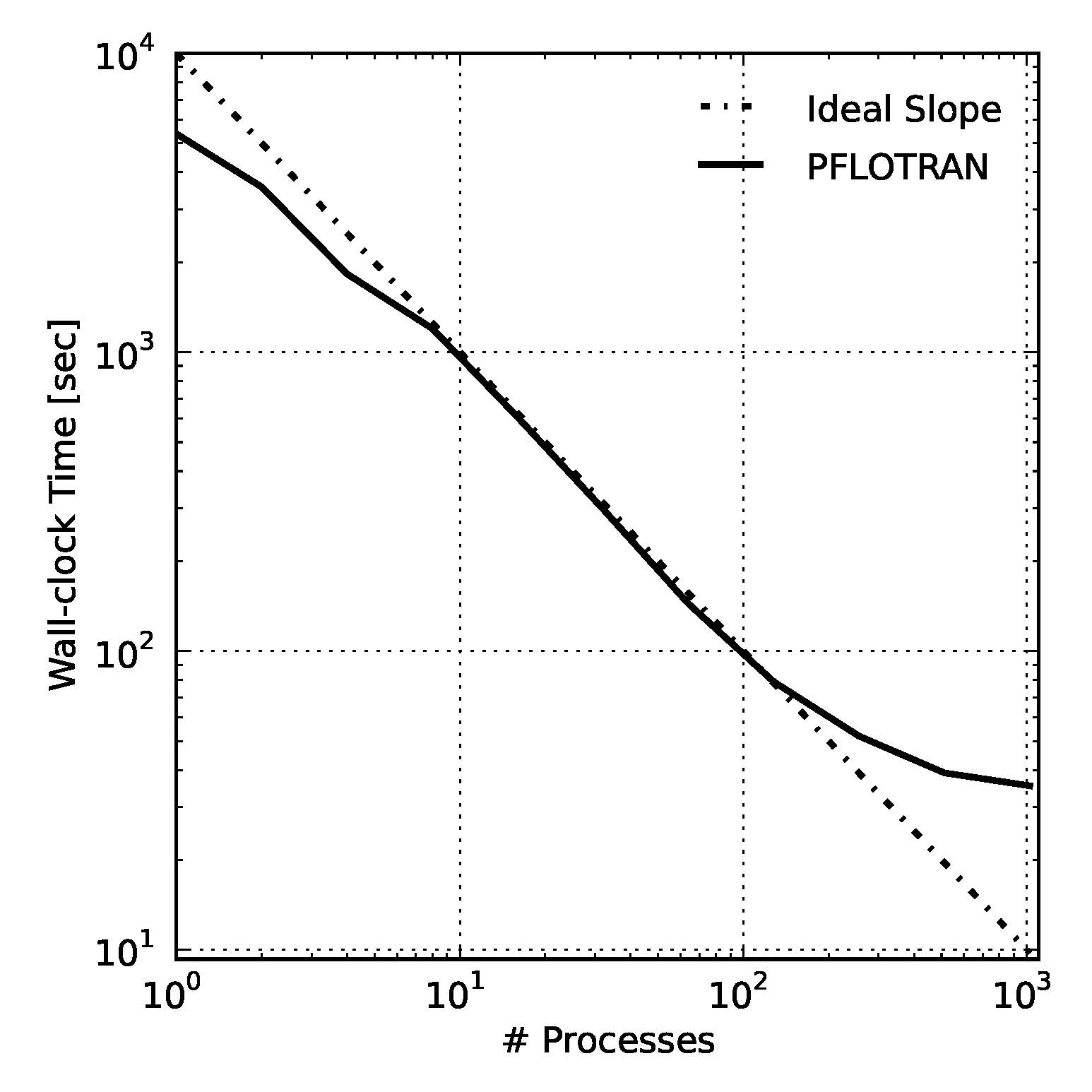
PFLOTRAN strong scaling for small copper leaching problem composed of 49K degrees of freedom (4096 cells and 12 primary species). The lack of scalability through 8 processes is due to memory contention within the Jaguar XK6 node whereas the code is exceptionally scalable from 8-128 processes. Note that at 128 processes, each process possesses a mere 384 dofs (32 cells).
CO2-water multiphase
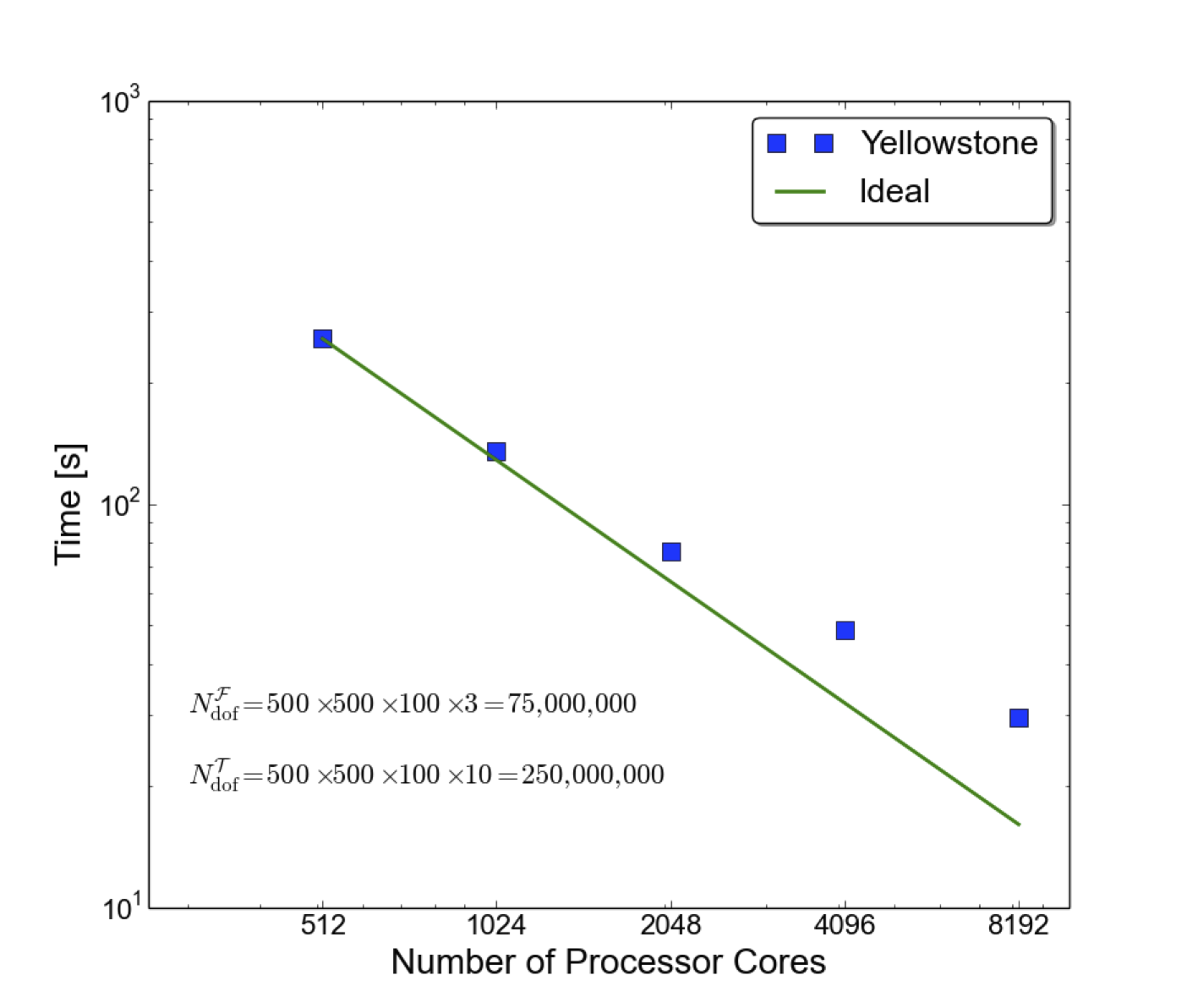
Scaling of PFLOTRAN on Yellowstone with up to 8192 processor cores. The time refers to 10 flow steps and 14 transport steps with I/O turned off. A grid 500 × 500 × 100 is used with 3 degrees of freedom per grid cell for flow and 10 for transport. Yellowstone is a 1.5 petaflop machine with 72,288 processor cores located at the NCAR Supercomputing Center (NWSC), Cheyenne, Wyoming.
Multiple continuum model
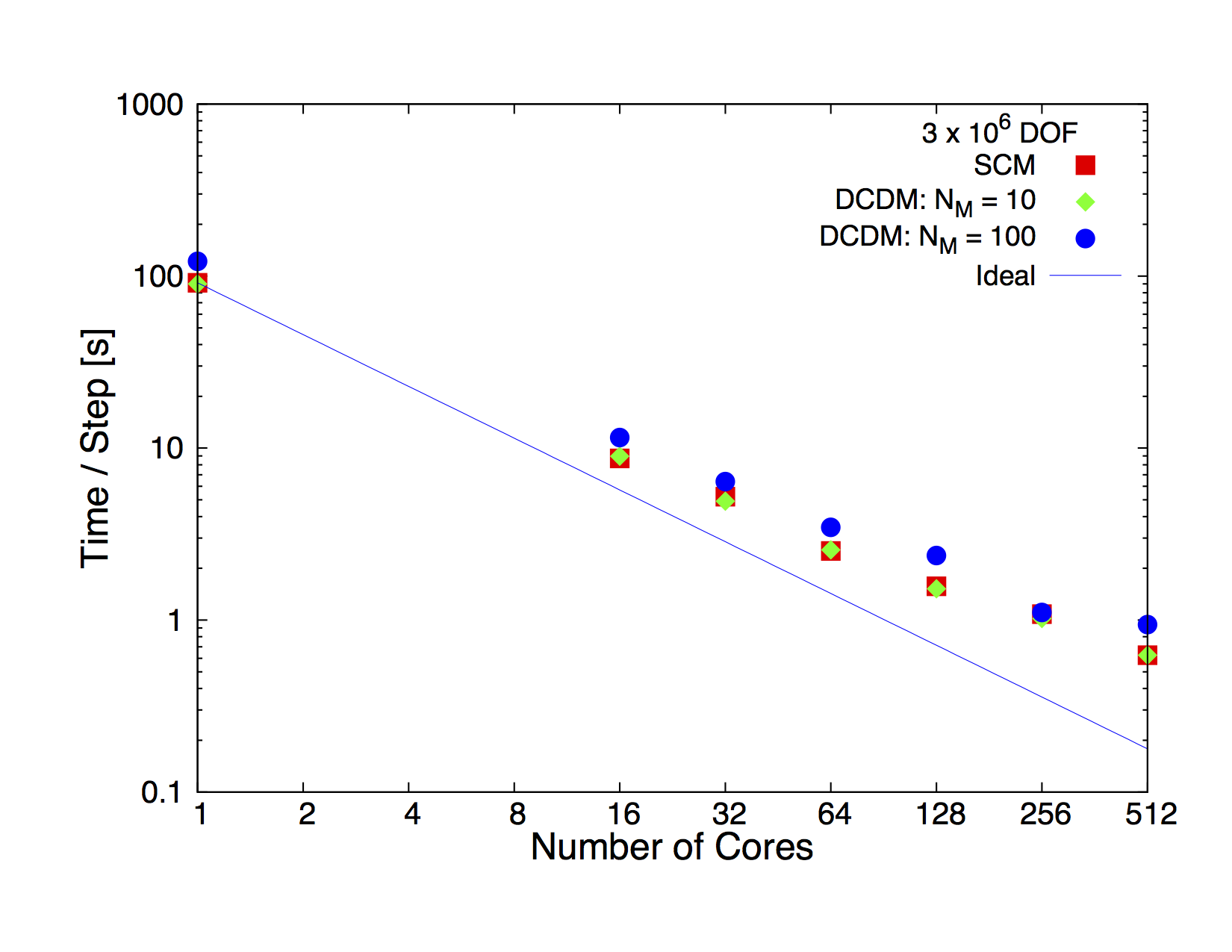
Strong scaling performance comparison of the dual continuum algorithm to the single continuum formulation for a domain size of 3 million matrix degrees of freedom (or 1 million matrix grid cells). In this problem, reactive transport was not considered and only mass and energy balance equations for the working fluid were solved. For the dual continuum case only heat transfer was considered. As can bee seen from the figure, the two cases of dual continuum models scale similar to the single continuum case. In addition, for the case with 10 fracture nodes per matrix node, with the total number of degrees of freedom (matrix plus fracture) being 13 million, an increase of nearly 3 times, the additional computational time is negligible. When the number of fracture nodes per matrix node is increased to 100, the increase in computational time is less than 10%. In this case the total number of degrees of freedom is 103 million which is an increase of over a factor of 30.